How Acontext Stores AI Messages?
Agent developers shouldn't be writing custom message converters every time providers change their APIs. You need to work with messages from OpenAI, Anthropic, and other providers—but each one structures messages differently. Without a unified approach, you end up with fragmented, inconsistent data that's hard to store, query, and learn from.
Agent developers shouldn't be writing custom message converters every time providers change their APIs. You need to work with messages from OpenAI, Anthropic, and other providers—but each one structures messages differently. Without a unified approach, you end up with fragmented, inconsistent data that's hard to store, query, and learn from.
Building reliable agent systems requires treating message data as first-class infrastructure. Acontext provides a unified and durable message layer that makes context observable, persistent, and reusable. You send messages in any format—OpenAI, Anthropic, or Acontext's unified format—and they just work.
This post explores how Acontext stores and normalizes multi-format messages, the architecture that makes it possible, and what this means for building production-ready agents.
The Problem: Format Fragmentation
Today, agent context is scattered across different formats, storage systems, and provider-specific structures. The result? Fragmented, transient, and nearly impossible to analyze over time.
Consider what happens when you build an agent that needs to work with multiple providers:
Format Fragmentation: Each provider uses different message structures. OpenAI uses tool_calls[] with nested function.name and function.arguments, while Anthropic uses tool_use[] with name and input. Without normalization, you can't query or analyze messages uniformly.
Information Loss: During format conversion, important metadata (tool call IDs, message names, source format) often gets lost or becomes inconsistent. You end up with incomplete context that can't be reliably used for learning or debugging.
Storage Inefficiency: Storing large message payloads (images, files, long text) directly in PostgreSQL bloats the database and slows queries. But storing everything in object storage makes querying complex and loses transactional guarantees.
Provider Lock-in: Systems become tightly coupled to one provider's format. When a new provider emerges or an existing one updates their API, you're rewriting converters and risking breaking changes.
All these challenges stem from one root cause: message data is not treated as first-class infrastructure.
We don't need another database or storage system. We need a unified layer that accepts messages in any format, normalizes them to a consistent representation, and stores them efficiently—all while preserving every piece of context. That's what Acontext does.
The Solution: Unified Message Processing
Acontext's message processing system provides a single interface through which your agents can flexibly receive, normalize, and store messages from any provider. Here's how it works:
Multi-Format Support
Instead of requiring clients to convert messages to a single format, Acontext accepts messages in their native format (OpenAI, Anthropic, or Acontext's unified format) and normalizes them internally.
This means:
- Clients can use their existing SDKs without modification
- The system validates messages using official provider SDKs, ensuring spec compliance
- Format conversion happens once at ingestion, not repeatedly during processing
Acontext uses normalizers as adapters that translate provider-specific formats into a unified internal representation, so your downstream systems only need to understand one format.
Complete Context Preservation
Different providers structure messages differently. Without careful normalization, this information gets lost.
Acontext preserves all metadata by:
- Storing the original source format in message metadata
- Unifying field names (e.g.,
tool_use→tool-call,input→arguments) - Preserving provider-specific metadata in a flexible
metafield
This ensures downstream systems can handle tool calls uniformly while still accessing original provider-specific information when needed.
Efficient Hybrid Storage
Messages can contain large payloads—images, files, or long text content. Storing these directly in PostgreSQL would bloat the database and slow queries.
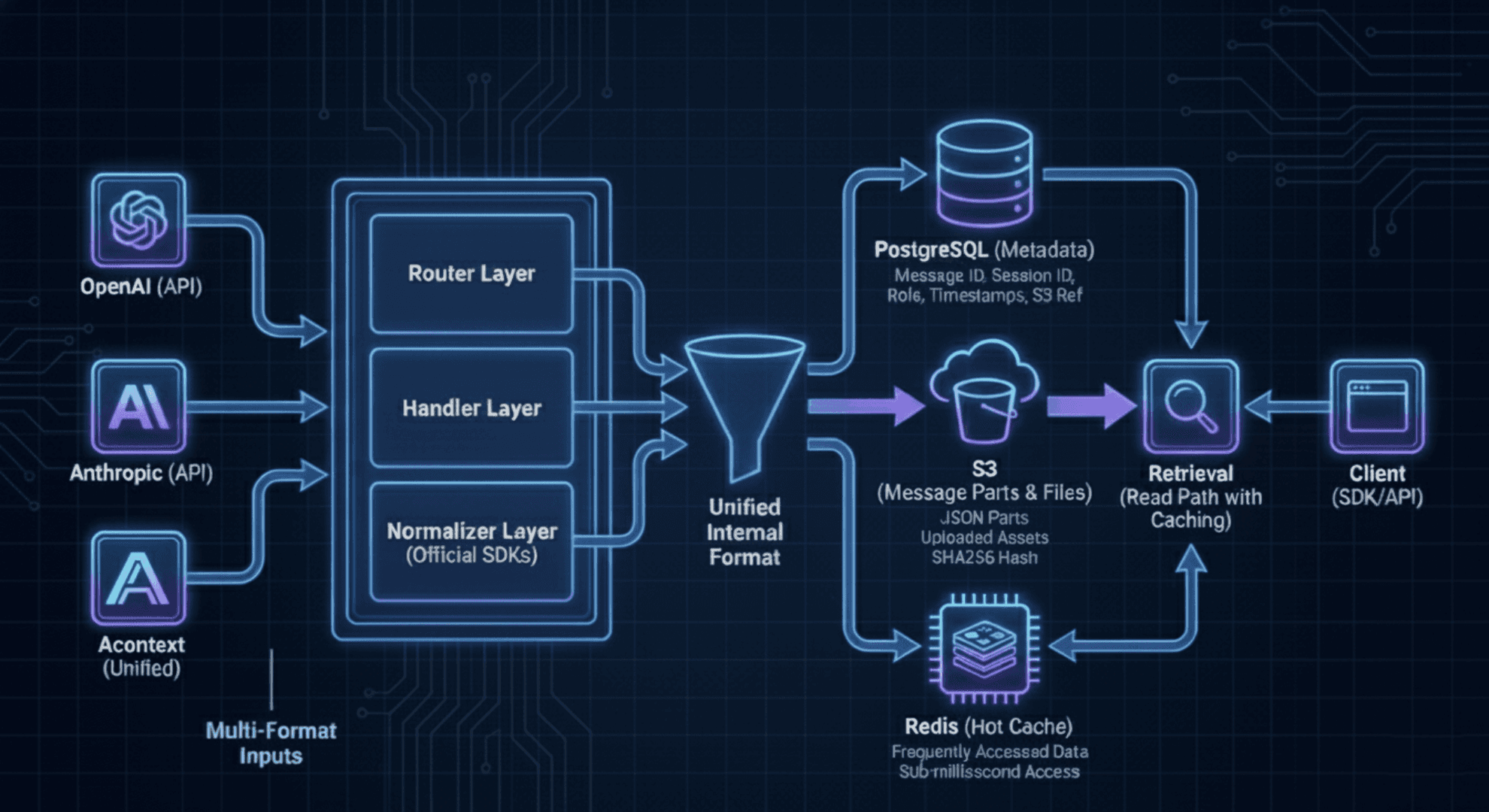
Acontext uses a three-tier storage strategy:
- PostgreSQL stores lightweight metadata (message ID, session ID, role, timestamps)
- S3 stores the actual message parts as JSON files, referenced by the database
- Redis provides hot cache for frequently accessed message parts, reducing S3 reads
- Content-addressed storage using SHA256 hashes enables automatic deduplication
This separation allows the database to remain fast for queries while S3 handles large payloads efficiently. Redis caching ensures hot data is served instantly without hitting S3, dramatically improving read performance for active sessions. It's like having a filesystem with intelligent caching for your agent's context data.
Provider Flexibility
As new providers emerge or existing providers update their formats, the system needs to adapt without breaking existing functionality.
Acontext achieves this through:
- Pluggable normalizers: Each provider has its own normalizer that can be updated independently
- Unified internal format: Downstream systems only need to understand one format
- Format versioning: Message metadata tracks the source format, enabling format-specific handling when needed
Architecture: Layered Design
Acontext's message processing follows a clean layered architecture that separates concerns, making it easy to add new providers or modify existing behavior:
┌─────────────────────────────────────────────────────────────────┐
│ HTTP Request │
│ (OpenAI / Anthropic / Acontext unified format) │
└────────────────────────────┬────────────────────────────────────┘
│
▼
┌─────────────────┐
│ Router Layer │
│ • Routing │
│ • Auth │
│ • Params │
└────────┬────────┘
│
▼
┌─────────────────┐
│ Handler Layer │
│ • Content-Type │
│ • Parsing │
│ • Validation │
└────────┬────────┘
│
▼
┌─────────────────┐
│ Normalizer │
│ • OpenAI SDK │
│ • Anthropic SDK│
│ • Format Conv. │
└────────┬────────┘
│
▼
┌─────────────────┐
│ Service Layer │
│ • File Upload │
│ • S3 Storage │
│ • Redis Cache │
│ • Ref Counting │
└────────┬────────┘
│
▼
┌─────────────────┐
│ Repository │
│ • PostgreSQL │
│ • Transactions │
└─────────────────┘Router Layer: Handles HTTP routing, authentication, and extracts URL parameters. It's format-agnostic and focuses on request routing.
Handler Layer: Detects content type (JSON vs multipart), parses the request, and validates the format parameter. It orchestrates the normalization process but doesn't perform format-specific parsing.
Normalizer Layer: This is where format-specific logic lives. Each provider has its own normalizer that:
- Uses the official provider SDK for validation (ensuring spec compliance)
- Converts provider-specific structures to the unified internal format
- Preserves metadata and handles edge cases
Service Layer: Handles business logic—file uploads, S3 storage, Redis caching, reference counting. It works with the unified format, so it doesn't need to know about provider differences. The caching layer ensures hot data is served instantly while maintaining S3 as the source of truth.
Repository Layer: Manages database operations and transactions. It stores metadata in PostgreSQL and references to S3 objects.
This separation means adding a new provider only requires implementing a new normalizer—the rest of the system remains unchanged. It's designed to scale with your needs.
Data Flow: From Request to Storage
Here's how a message flows through the system:
┌──────────────┐
│ Client │
│ (SDK/API) │
└──────┬───────┘
│ POST /sessions/{id}/messages?format=openai
│ Content-Type: application/json
▼
┌─────────────────────────────────────────────────────────────┐
│ Acontext API │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────────┐ │
│ │ Router │───▶│ Handler │───▶│ Normalizer │ │
│ │ │ │ │ │ (OpenAI SDK)│ │
│ └──────────┘ └──────────┘ └──────┬───────┘ │
│ │ │
│ │ Unified Format │
│ ▼ │
│ ┌──────────────┐ │
│ │ Service │ │
│ │ • Upload │ │
│ │ • Dedupe │ │
│ │ • Cache │ │
│ └──────┬───────┘ │
│ │ │
└─────────────────────────────────────────┼───────────────────┘
│
┌─────────────────────┼─────────────────────┐
│ │ │
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ PostgreSQL │ │ S3 │ │ Redis │
│ │ │ │ │ │
│ • Message ID │ │ • Parts JSON │ │ • Hot Cache │
│ • Session ID │ │ • Files │ │ • SHA256 key │
│ • Role │ │ • SHA256 key │ │ • Fixed TTL │
│ • Asset ref │ │ │ │ │
│ • Metadata │ │ │ │ │
│ (JSONB) │ │ │ │ │
│ • Source │ │ │ │ │
│ • Format │ │ │ │ │
│ • Timestamps │ │ │ │ │
└──────────────┘ └──────────────┘ └──────────────┘Step 1: Ingestion
- Client sends message in native format (OpenAI, Anthropic, or Acontext's unified format)
- Router extracts format parameter and routes to handler
Step 2: Normalization
- Handler detects content type and parses request
- Normalizer uses official provider SDK to validate and convert
- Message is transformed to unified internal format
Step 3: Storage (Write Path)
- Service layer handles file uploads and calculates SHA256 hashes
- Content-addressed storage enables automatic deduplication
- S3: Parts JSON and files uploaded to S3, organized by SHA256 hash
- Redis: After successful S3 upload, parts data cached in Redis with fixed TTL
- PostgreSQL: Message metadata (ID, session ID, role, timestamps, source format) and S3 asset reference stored
- Reference counting ensures safe deletion when messages are removed
Step 4: Retrieval (Read Path with Caching)
- System queries PostgreSQL for message metadata
- For each message, first checks Redis cache using SHA256 hash from metadata
- Cache hit: Parts returned instantly from Redis (sub-millisecond latency)
- Cache miss: Parts loaded from S3, then cached in Redis for subsequent requests
- This ensures hot data (recently accessed messages) is served with minimal latency
Format Comparison: Provider Differences
Each provider structures messages differently. Here's how they compare:
Feature | OpenAI | Anthropic | Acontext (Unified) |
Content Structure | String or array | Always array | Always array |
Tool Calls |
|
|
|
Tool Results |
|
|
|
Images |
|
|
|
Metadata | Limited | Limited | Flexible |
Source Tracking | No | No |
|
Example: Same Message, Different Formats
OpenAI Format:
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "I'll check the weather for you."
}
],
"tool_calls": [
{
"id": "call_123",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"location\":\"San Francisco\"}"
}
}
]
}Anthropic Format:
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "I'll check the weather for you."
},
{
"type": "tool_use",
"id": "toolu_123",
"name": "get_weather",
"input": {
"location": "San Francisco"
}
}
]
}Acontext Unified Format:
{
"role": "assistant",
"parts": [
{
"type": "text",
"text": "I'll check the weather for you."
},
{
"type": "tool-call",
"meta": {
"name": "get_weather",
"arguments": "{\"location\":\"San Francisco\"}",
"id": "call_123"
}
}
],
"meta": {
"source_format": "openai"
}
}The unified format means downstream systems only need to understand one structure, while original format information is preserved for debugging and auditing.
Storage: Three-Tier Architecture (PostgreSQL + S3 + Redis)
Why Three-Tier Storage?
Storing everything in PostgreSQL leads to database bloat and slow queries. Storing everything in S3 makes querying complex and loses transactional guarantees. Reading from S3 on every request adds latency. Acontext uses PostgreSQL for metadata, S3 for durable storage, Redis for hot cache—the best of all worlds.
PostgreSQL stores:
- Message identifiers (ID, session ID, parent ID)
- Lightweight fields (role, timestamps, status)
- S3 reference (asset metadata pointing to the parts JSON file)
- Message-level metadata (source format, name, etc.)
S3 stores:
- Message parts as JSON files (content-addressed by SHA256)
- Uploaded files (images, documents, etc.)
- Organized by project and date (format:
parts/{project_id}/{YYYY/MM/DD}/{sha256}.json) for efficient access - Serves as the source of truth for all message content
Redis caches:
- Frequently accessed message parts (hot data)
- Keyed by SHA256 hash for content-based caching
- Fixed TTL strategy ensures automatic expiration and bounded memory usage
- Dramatically reduces S3 read operations for active sessions
This three-tier architecture allows fast SQL queries on metadata, efficient storage for large payloads, and instant access to hot data. It's designed like a filesystem with intelligent caching for your agent's context data.
Content-Addressed Storage and Deduplication
When the same content is uploaded multiple times (e.g., the same image used in different messages), Acontext automatically deduplicates it:
- Calculate SHA256 hash of the content
- Check if an object with this hash already exists in S3
- If found, return the existing object metadata
- If not found, upload with a path like
parts/{project_id}/{YYYY/MM/DD}/{sha256}.json
This means identical content is stored only once, saving storage costs and improving cache efficiency. The SHA256-based addressing also enables efficient Redis caching—the same hash is used as the cache key, so identical content benefits from cache hits regardless of which message references it. It's automatic—you don't need to think about it.
Reference Counting for Safe Deletion
When a message is deleted, we can't immediately delete its S3 assets—other messages might reference the same content. Acontext uses reference counting:
- Each asset has a
ref_countin the database - When a message references an asset, increment the count
- When a message is deleted, decrement the count
- Only delete from S3 when
ref_countreaches zero
This is handled atomically at the database level using PostgreSQL's row-level locking, eliminating race conditions without application-level synchronization. It's safe, automatic, and efficient.
Redis Hot Cache for Performance
To minimize latency when reading messages, Acontext uses Redis as a hot cache layer:
On Write (SendMessage):
- After successfully uploading parts to S3, the parts data is cached in Redis
- Cache key:
message:parts:{sha256}(using SHA256 for content-based caching) - Uses a fixed TTL strategy: entries automatically expire after a set duration
On Read (GetMessages):
- System first checks Redis cache using the SHA256 hash from message metadata
- Cache hit: Parts returned instantly from Redis (sub-millisecond latency)
- Cache miss: Parts loaded from S3, then cached in Redis for subsequent requests
- This ensures recently accessed messages are served with minimal latency
Benefits:
- Reduced S3 reads: Hot data (active sessions) rarely hits S3
- Lower latency: Cache hits are orders of magnitude faster than S3 reads
- Content-based caching: Same content (same SHA256) benefits from cache regardless of which message references it
- Automatic cache management: Fixed TTL strategy ensures cache automatically expires stale entries without manual intervention or complex eviction policies
- Predictable behavior: Simple, deterministic expiration makes cache behavior easy to reason about
- Bounded memory: Cache size naturally self-regulates as entries expire, preventing unbounded growth
The cache is transparent—if Redis is unavailable, the system gracefully falls back to S3. This ensures reliability while maximizing performance for the common case.
Parsing: Multi-Format Normalization
Using Official SDKs for Validation
Rather than manually parsing JSON and hoping we got it right, Acontext uses official provider SDKs:
- OpenAI: Uses openai-go↗ types
- Anthropic: Uses anthropic-sdk-go↗ types
This ensures:
- Type safety: Compile-time checking of message structure
- Spec compliance: SDKs stay updated with provider changes
- Error handling: SDKs handle edge cases we might miss
The normalizers act as thin adapters that use SDK types for parsing, then convert to the unified format. It's reliable, maintainable, and future-proof.
The Unified Internal Format
Acontext converts all formats to a unified structure:
{
"role": "user",
"parts": [
{
"type": "text",
"text": "Hello"
},
{
"type": "tool-call",
"meta": {
"name": "get_weather",
"arguments": "{\"location\":\"SF\"}"
}
}
],
"meta": {
"source_format": "openai"
}
}This unified format means:
- Downstream systems only need to understand one structure
- Tool calls are handled uniformly regardless of source
- Original format is preserved in metadata for debugging/auditing
Use Cases: Real-World Applications
Multi-Provider Agent Systems
You're building an agent that needs to work with both OpenAI and Anthropic, depending on the task. Without Acontext, you'd need separate storage systems, different query logic, and custom converters for each provider.
With Acontext:
from acontext import AcontextClient
client = AcontextClient(api_key="your-api-key")
# Send OpenAI format message
openai_message = {"role": "user", "content": "Hello"}
client.sessions.send_message(
session_id=session_id,
blob=openai_message, # Native OpenAI format
format="openai"
)
# Send Anthropic format message
anthropic_message = {"role": "user", "content": "Hello"}
client.sessions.send_message(
session_id=session_id,
blob=anthropic_message, # Native Anthropic format
format="anthropic"
)
# Query uniformly
messages = client.sessions.get_messages(session_id=session_id)
# All messages in unified format, regardless of sourceContext Learning and Analysis
You want to analyze tool usage patterns across all your agent interactions, but messages are stored in different formats with inconsistent structures.
With Acontext:
- All messages normalized to unified format
- Tool calls queryable uniformly:
WHERE parts->>'type' = 'tool-call' - Source format preserved for debugging:
WHERE meta->>'source_format' = 'openai' - Fast queries on metadata, efficient storage for payloads
Large Payload Handling
Your agent processes images, documents, and long-form content. Storing everything in PostgreSQL would bloat the database, but object storage makes querying difficult.
With Acontext:
- Metadata in PostgreSQL for fast queries
- Payloads in S3 for efficient storage
- Redis cache for instant access to hot data
- Automatic deduplication saves storage costs
- Reference counting ensures safe deletion
Provider Migration
You're migrating from OpenAI to Anthropic, or need to support both during a transition period. Without normalization, you'd need separate code paths and risk data inconsistency.
With Acontext:
- Send messages in either format to the same API
- Unified storage means consistent queries
- Source format tracked for auditing
- No code changes needed for downstream systems
Built to Scale
Acontext's message processing is designed to grow with your needs:
- Add new providers: Just implement a new normalizer
- Handle large payloads: Hybrid storage scales automatically
- Support new formats: The unified internal format remains stable
- Maintain reliability: Official SDK validation ensures spec compliance
It's infrastructure that works, so you don't have to think about it.
Vision: Message Data as First-Class Infrastructure
Building a multi-format message processing system is about treating message data as first-class infrastructure. By providing a unified layer that normalizes, stores, and preserves context data, Acontext enables agents to work with consistent, observable, and learnable context.
This is what a Context Data Platform should do: make context data observable, persistent, and reusable, so you can focus on building agents that deliver real value.
You focus on building agents that solve real problems, not on babysitting message formats.
The system:
- Accepts messages in any supported format (OpenAI, Anthropic, or Acontext's unified format)
- Normalizes them to a unified internal representation
- Stores them efficiently using hybrid storage
- Preserves all necessary metadata
This enables Acontext to serve as a reliable foundation for context data management, allowing your agents to work with consistent, queryable, and learnable context data—the foundation for self-learning AI systems.