New Features in Acontext: Context Engineering in a Few Lines of Code
Learn how Acontext simplifies context engineering from days of manual work to just a few hours,and why a context data platform matters for production agents.
When building AI agents, the real source of complexity is rarely the model itself. It's the context around it.
Model capabilities have improved rapidly, but anyone who has built a production-grade agent knows the pattern: as soon as the system runs longer, handles tools, or spans multiple turns, the hard work shifts away from prompting and into context engineering.
Why does context engineering become the real bottleneck?
In practice, 'context engineering' is not an abstract idea. It is a collection of very concrete engineering tasks:
- Storing text, images, memories, artifacts, tool calls...
- Managing sessions that grow unbounded over time
- Switching message formats across OpenAI, Anthropic, and Gemini
- Truncating or filtering context without breaking semantics
- Answering: 'What exactly did the LLM see at that moment?'
These tasks share a few traits: almost every production agent runs into them; they are ongoing costs, not one-time work; they tend to be implemented as ad hoc scripts and glue code.
As a result, teams often spend more time maintaining context logic than improving the agent's actual reasoning or behavior.
A Simpler Pattern: Context Data as a Unified Layer
The problem is not that context engineering is inherently complex, but that it usually lives in the wrong place.
A more inspiring mental model is to treat context as a system-level data concern rather than as prompt logic.
This model has three core ideas:
- Context data maintains complete Raw messages and artifacts should be stored intact, not rewritten or mutated as the session evolves.
- Editing is in visible control, not a mutation Truncation, filtering, and token control should happen at retrieval, while the original session remains unchanged. Developers can utilize clear context window usage to determine if they need to edit the context.
- Rules over scripts Instead of scattering heuristics throughout business logic, developers can describe how context should be shaped using declarative rules.
With this shift, context engineering becomes predictable and reusable rather than fragile and bespoke.
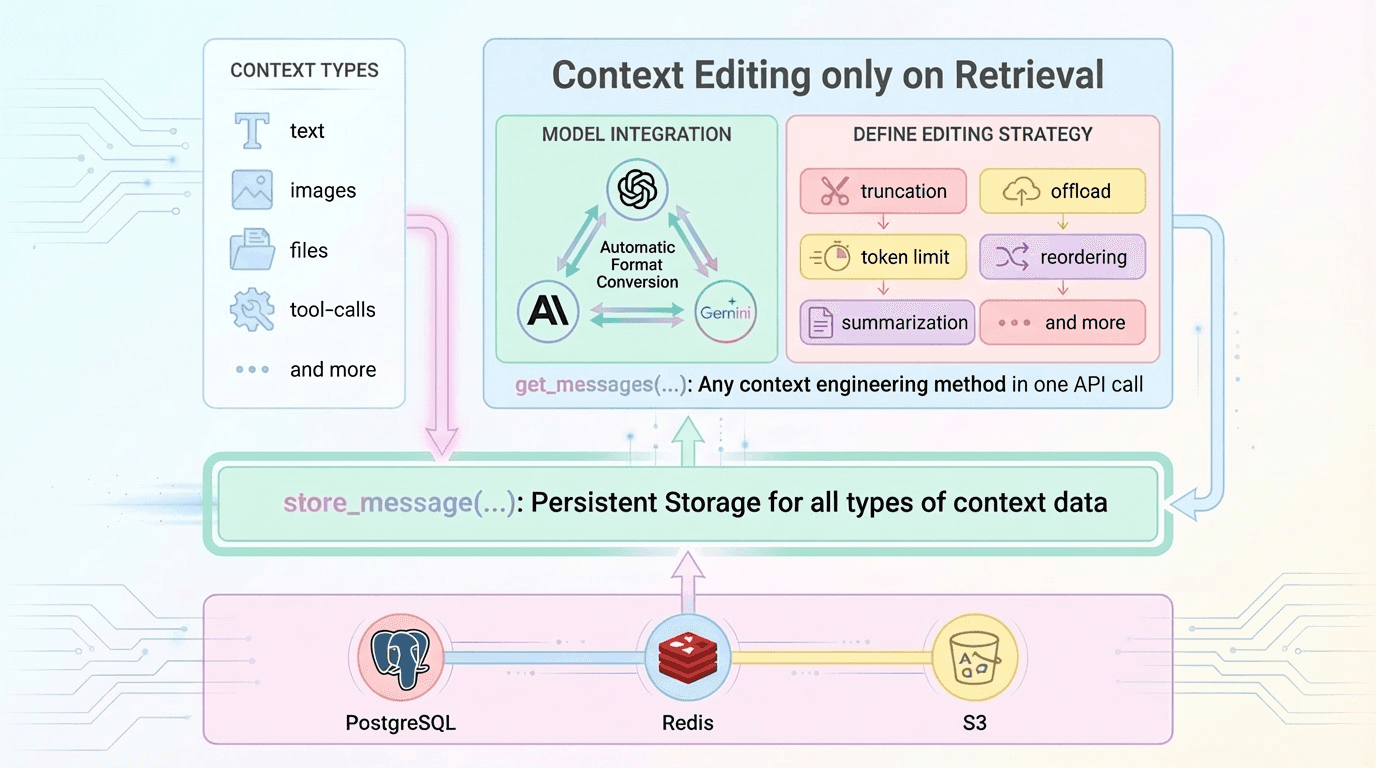
Acontext Simplifies Context Engineering in Two APIs
Seen this way, 'a few lines of code' does not mean doing less work. It means moving complexity into the system layer, where it can be handled consistently.
Acontext follows this approach with two APIs: store_message() and get_messages()
- Raw context is stored once
- Context editing happens only when messages are retrieved
- Editing behavior is defined through explicit strategies
- The same rules apply across agents and sessions
Code in Action: Context Editing On-the-fly
The example below shows how context editing is moved from application logic into a declarative read step.
Instead of pulling messages, counting tokens, trimming history, and rebuilding model inputs in code, the application describes its editing rules once and passes them to get_messages. Acontext applies those rules consistently and returns an edited view of the session.
Because editing happens at read time, changing context behavior does not require rewriting storage logic or reprocessing historical data. You can adjust strategies, compare different views, or reuse the same rules across agents without duplicating code.
Editing Strategies Ready-to-use:
get_token_counts()You can inspect the current token size of a session before editing.
Benefit: context editing becomes data-driven instead of heuristic-based.
token_limitTruncates the session by removing the oldest messages until the total token count is within a specified limit. Tool-call and tool-result pairs are preserved correctly.
Benefit: no custom truncation logic, no broken tool histories.
remove_tool_resultReplaces older tool result contents with a placeholder, while keeping recent results intact.
Benefit: large, verbose tool outputs no longer consume context without losing execution structure.
remove_tool_call_paramsRemoves arguments from older tool calls, keeping only IDs and names so tool-results can still reference them.
Benefit: reduces token usage while preserving causal links between tool calls and results
middle_outoffload_to_logremove_by_completed_tasks- ...
from acontext import AcontextClient
client = AcontextClient(
base_url="http://localhost:8029/api/v1",
api_key="sk-ac-your-root-api-bearer-token"
)
edited_session = client.sessions.get_messages(
session_id="session-uuid"
edit_strategies=[
{"type": "token_limit", "params":{"limit_tokens": 20000}},
{"type": "remove_tool_result", "params": {"keep_recent_n_tool_result": 3}},
...
],
)
original_session = client.sessions.get_messages(
session_id="session-uuid"
)In practice, this reduces the amount of glue code developers maintain, shortens iteration cycles when tuning context behavior, and makes context engineering more predictable rather than ad hoc.
Why a Context Data Platform Matters for Production Agents
This unified data layer abstraction is not about making AI agents look better in a demo. It is about making them behave reliably in real production environments, where context grows, tools run repeatedly, and failures are expensive.
In practice, teams begin to see clear, concrete improvements:
- Long-running tasks fail less often because context growth is handled safely and consistently
- Agent behavior becomes predictable and reproducible across runs, environments, and model upgrades
- Debugging no longer depends on guessing what the model may have seen at a given moment
- Context engineering recedes into the background, treated as infrastructure rather than application logic
When context is treated as a first-class system concern through a dedicated data platform, production agents become easier to reason about, easier to debug, and significantly easier to maintain as systems evolve.
The Way Forward
Context engineering does not have to take days of manual work.
With Acontext, tasks that once required days of custom wiring can be done in hours: safely, consistently, and without rewriting the same glue code.
That is what simplifying context engineering means in practice.
If this aligns with how you build agents, please do try Acontext in a real workflow.
Share what works, what breaks, and what you wish existed.
Join the community, give feedback, and help agent builders shape the open-source roadmap.